Overview
- Introduction
- Why another API?
- How does it work?
- Install in VIVO 1.11
- Install in VIVO 1.10
- Install in VIVO 1.9
- Install in VIVO 1.8
- Configuration
- Implementations
- Cross-site distributions
- Javadoc
- Release notes
Project Documentation

The Data Distribution API takes its configuration from VIVO’s content triple-store. Usually this means that one or more files of RDF are placed in the VIVO home directory, to be loaded when VIVO starts up.
The Data Distribution API works with any Java object that implements the DataDistributor interface. However, the strategy has been to create a suite of general purpose distributors that can be configured for a variety of use cases. In this way, the RDF files may contain everything that is needed to provide a new data source.
To illustrate, let’s look at a simple request for data. The data will be used to populate a “sunburst” visualization in the browser. For now, the data is hard-coded in a file on the server, formatted to look like the response to a SPARQL SELECT query.
The relevant section of the configuration file might look like this:
:collaborations
a ddapi:file.FileDistributor ;
:actionName "collaboration_sunburst" ;
:path "dataCache/cached_collab_data.json" ;
:contentType "application/sparql-results+json" .
FileDistributor is one of the standard classes provided with the Data Distribution API. It simply copies the contents of a file into an HTTP response.
So, if the API controller receives a request like this:
http://scholars.cornell.edu/api/dataRequest/collaboration_sunburst
it will respond by
As the “sunburst” visualization is developed, we might choose to drive it from data taken directly from the triple-store. In that case, the configuration file might look like this:
:collaborations
a ddapi:rdf.SelectFromContentDistributor ;
:actionName "collaboration_sunburst" ;
:query """
PREFIX vivo: <http://vivoweb.org/ontology/core#>
SELECT *
WHERE {
?grant a vivo:Grant .
?grant rdfs:label ?grantTitle .
}
""" .
Again, SelectFromContentDistributor is provided with the Data Distribution API. It executes a SPARQL SELECT query against the VIVO content models, and copies the result into an HTTP response.
Now, if the API controller receives the same request:
http://scholars.cornell.edu/api/dataRequest/collaboration_sunburst
it will respond by
Each type of request is identified by a name. The request might also accept parameters, although that wasn’t shown in the example. JavaScript code on the browser requests data by that name and parameters. The JavaScript has no knowledge of how the response was produced. It merely requests the data set and creates a visualization from the response.
Each request type is configured by a site administrator, so there is no opportunity for users to make unexpected or unauthorized requests.
The actual source of the data is hidden from the JavaScript request. Site administrators are free to change the mechanism that provides the data, as shown in the example.
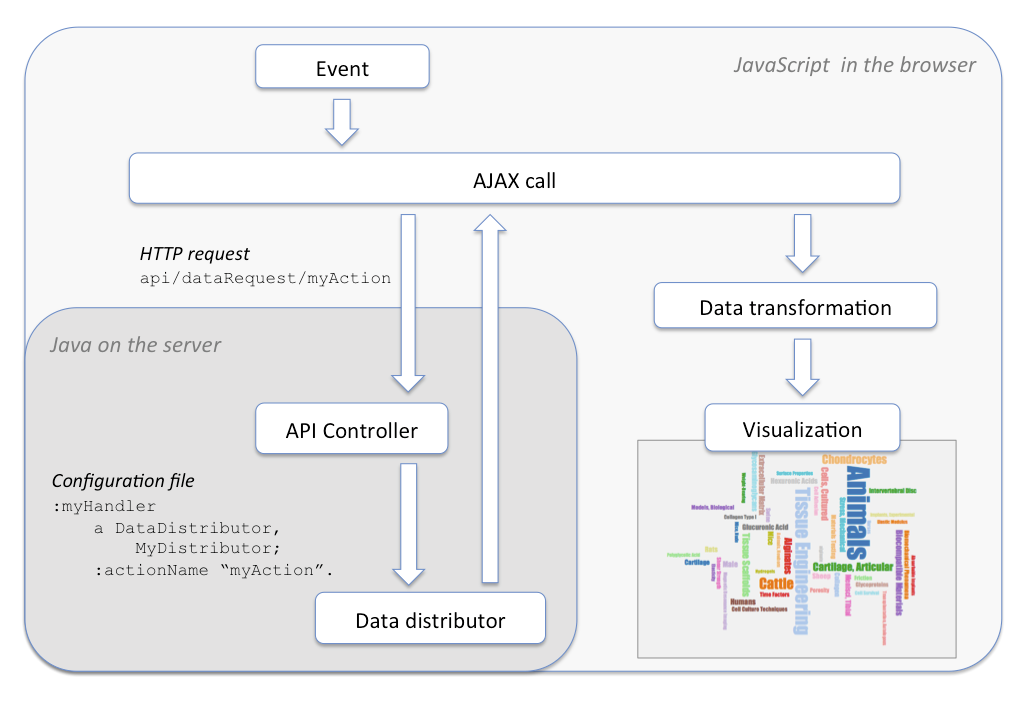
The display model in VIVO’s configuration triple-store associates data requests with the means of satisfying them. The most common way to do this is to create one or more files of RDF to be loaded at startup.
The configuration for each request includes the name of a Java class that will supply the data, and any parameters that the class requires. The Java class implements the DataDistributor interface. The API controller asks the distributor class to produce the data, and the controller routes the data to the user.
One of the powerful concepts in this design is that the Java class can be written as special-purpose code for a single use, or as general-purpose code which can be configured for each use case. We expect to see more general-purpose DataDistributor classes, such as:
In spite of this, special-purpose code will remain the best solution for some unusual data sets.